
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 해외유학
- California State University Sacramento
- JVM아키텍처
- Kenneth Park
- 복수학위제도
- 파이데이아창의인재학과
- 개발일지
- 케네스
- 미국유학생활
- 만다라트프로젝트
- i-20
- 사이드프로젝트
- 자바 스터디
- 미국대학
- 유학생 준비물
- 미국유학생
- 개인 프로젝트 개발일지
- 비전공자 git
- java
- Java 스터디
- 미국유학
- 2+2
- F1학생비자
- 부산외대
- jpa
- 자바
- 유학생대학생활
- CSUS
- 미국대학생활
- 케네스로그
- Today
- Total
케네스로그
[자료구조/Java] Hash 해시 본문

Hash는 키(key)와 값(value)을 쌍으로 저장되는 자료구조를 말합니다. 배열에는 여러 키(Key)들이 저장되며, 해쉬 함수를 통해 해당되는 값을 가져옵니다. 키(Key)는 중복되지 않는 유니크한 값이어야하며, 값(value)은 중복이 가능합니다.
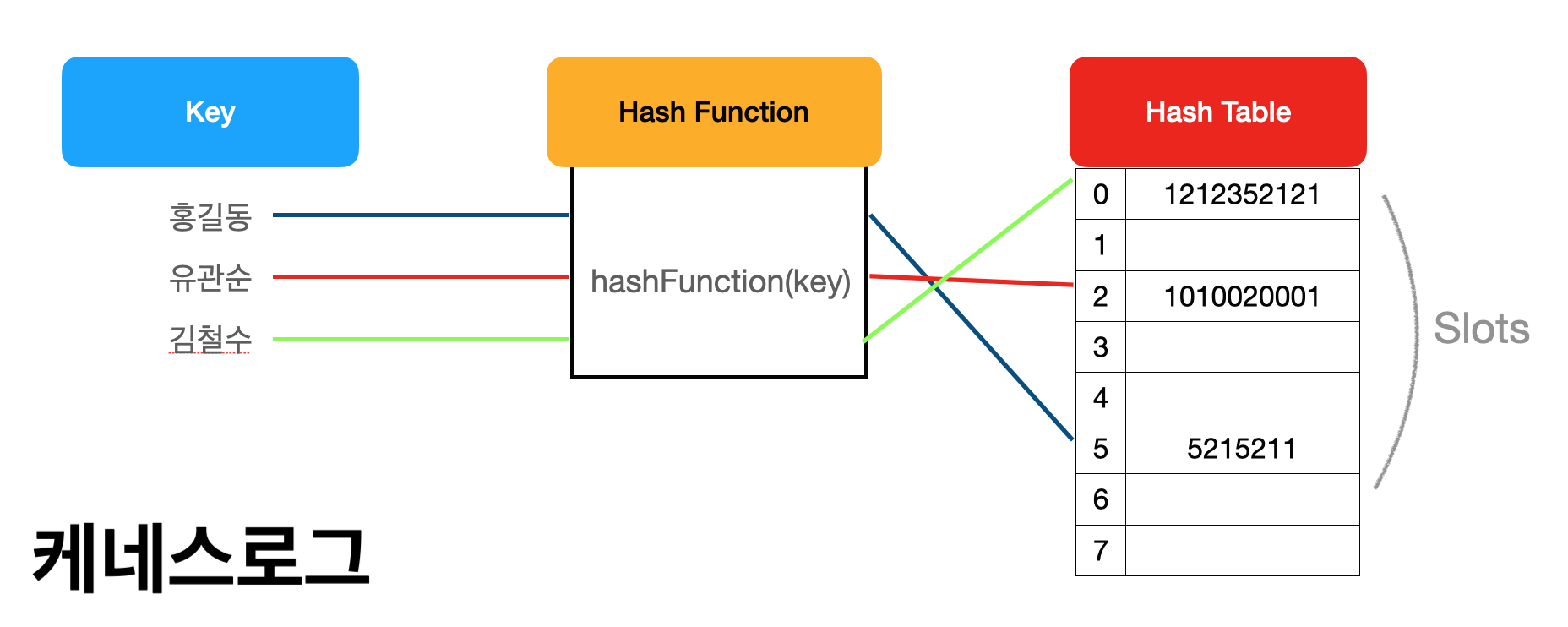
해시 테이블에서 데이터는 유니크한 인덱스 값에 따라 배열의 형태로 저장되빈다. 해시 함수는 키값에 대응되는 해시테이블의 인덱스를 연산하는 함수를 말합니다. 사용자는 키값을 넣어서 해시 테이블에 저장된 데이터의 위치를 받아 저장된 데이터에 접근할 수 있게 됩니다.
Terminology (+비유)
- Hash table - 주택단지
- Bucket - 아파트
- Entry - 호
- 해쉬함수 : 임의 데이터를 고정된 길이의 값으로 리턴해주는 함수
- 해쉬, 해쉬 값, 해쉬 주소: 해싱 함수를 통해 리턴된 고정된 길이의 값
- 해쉬 테이블: 키 값의 연산에 의해 직접 접근이 가능한 데이터 구조
- 슬롯: 해쉬 테이블에서 한 개의 데이터를 저장할 수 있는 공간
해시 메커니즘
Hashing은 키 값을 배열의 인덱스로 변환시키는 기술을 말합니다. 가장 쉽게 사용할 수 있는 기술이 나머지 연산(modulo)입니다.
기본적인 해시
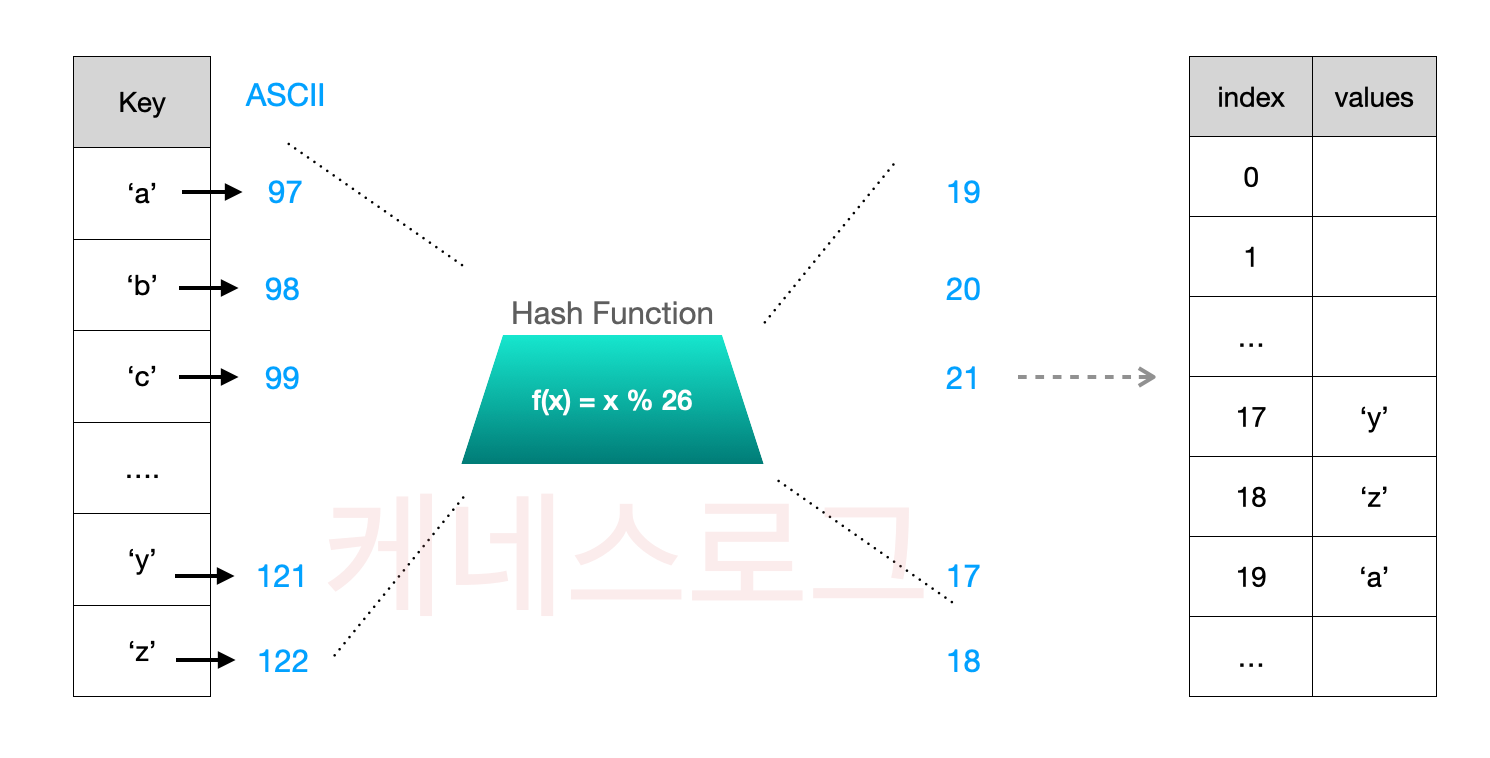
이해를 돕기위해 제한적인 상황에서 (키, 값)들이 해시함수에 의해 해시테이블에 저장되는 과정을 예시로 설명하고자 합니다.
오직 26가지의 키 값으로 해시테이블을 구성한다면, 해시 테이블은 26개의 인덱스를 지닌 배열로 생성됩니다. 아래는 해시 매커니즘을 순서대로 나열해보았습니다.
- key값은 알파벳 a-z까지 26가지가 존재합니다.
- 각 key값은 아스키코드의 10진법 표현으로 변환됩니다.
- 변환된 key값은 Hash함수를 통해 Hash Table의 인덱스로 변환됩니다.
- Hash함수는 주어진 정수값을 나머지(Modulo)연산을 통해 인덱스 값을 도출하며, 해쉬 테이블의 사이즈인 26을 연산에 사용합니다.
- Hash함수에 의해 도출된 해시테이블 인덱스에 값을 저장합니다.
Hash Table Collision
위의 예시에서는 예외적 상황이 일어날 수 없는 상황을 가정했습니다. 하지만, 만약 key값의 범주를 모든 캐릭터형으로 확장한다면 일반적인 나머지 연산(module)으로 해결할 수 없게 됩니다.
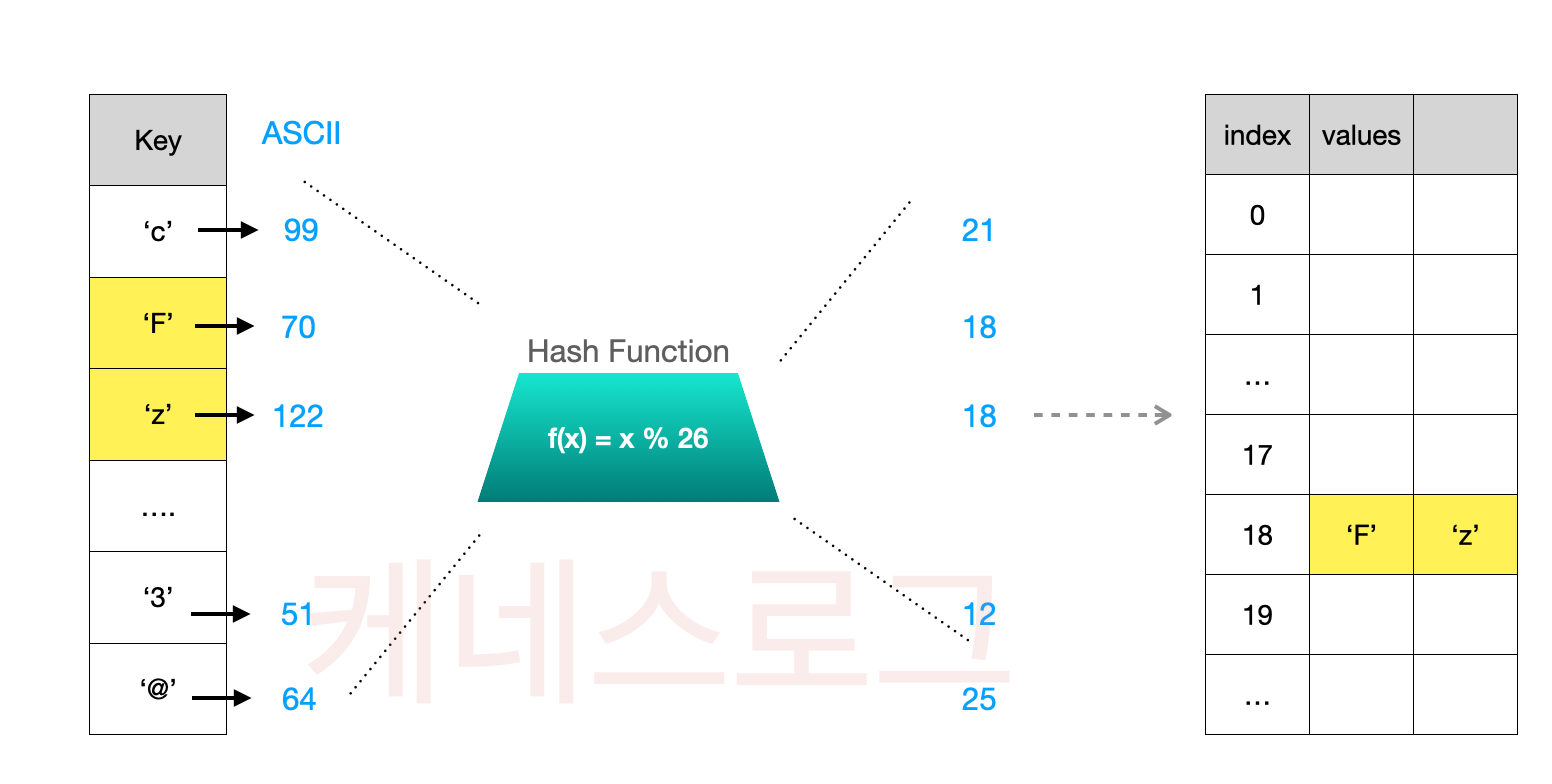
'F'와 'z'의 아스키코드는 각 70과 122입니다. 26개 인덱스를 가진 배열을 사용하게 될 경우, 키의 해쉬 함수 결과가 18로 같아지게 됩니다. 이렇게 되면, 18인덱스에 2개의 값을 저장해야 합니다. 이렇게 해시함수가 다른 입력에 대해 같은 출력을 하여, 같은 저장공간(bucket)에 두개 이상의 데이터가 저장되는 경우를 해시 충돌(Hash Collision)이라고 합니다. 이를 해결하기 위한 여러 테크닉이 존재합니다.
Hash Table dynamically sizing 해시 테이블 동적 사이징
load factor = total number of items stores / size of array
Hash Table이 동적으로 늘어날 수 있는 자료구조로 만들고, 저장된 데이터와 테이블 사이즈의 비율(Load Factor)에 따라 Hash Table의 크기 자체를 늘릴 수 있습니다.
Separate Chaining 체인 분리법
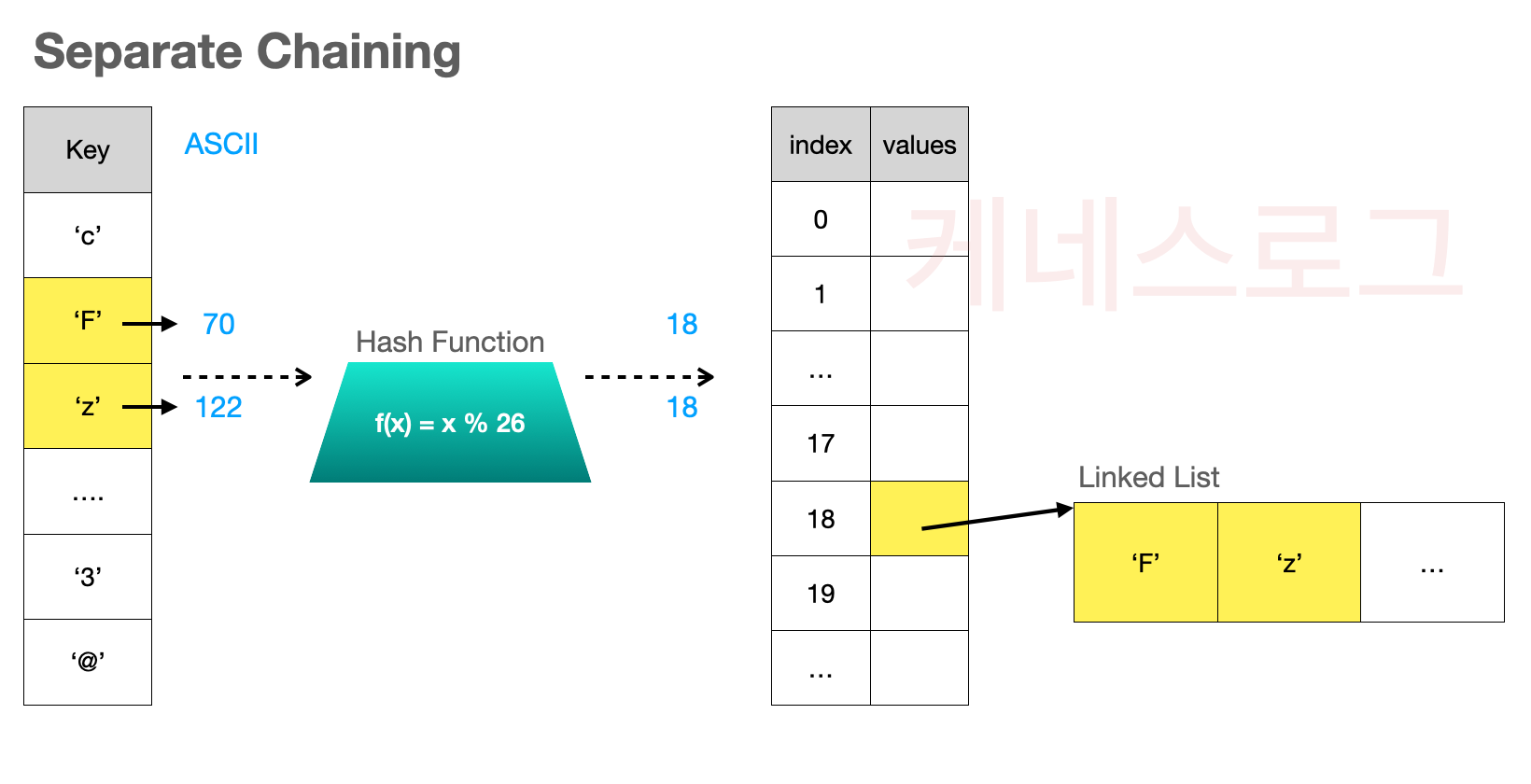
해시 테이블의 저장 공간(bucket)을 LinkedList로 구성하여 해시 충돌을 피하는 기법을 체인 분리법(separate chaining) 또는 폐쇄 주소법(closed addressing)이라고 합니다. 이때, LinkedList의 데이터가 저장되는 각 노드를 슬롯(slot)이라고 합니다.
- LinkedList라는 부가적인 자료구조를 사용함으로 성능 저하.
충돌이 많아져 리스트가 길어지면 탐색하는데에 O(n)까지 늘어날 수 있음. - 저장공간의 낭비가 발생
- Open Addressing으로 해결하기엔 데이터가 너무 많아서 Hash Table이 메모리 공간 낭비가 심하다면 고려할 수 있는 기법.
Open Addressing 개방 주소법
hash table의 주소에 이미 데이터가 저장되어 collision이 일어났을 때, 데이터 저장이 가능한 인접 인덱스에 저장하는 방법을 개방 주소법(open addressing)이라고 합니다. 모든 공간이 데이터를 저장할 수 있게 개방되어 있기 때문에 개방이라 합니다.
'Dev > 자료구조' 카테고리의 다른 글
| [자료구조/Java] Heap 힙 (0) | 2022.01.25 |
|---|---|
| [자료구조/Java] 이진탐색트리 - 탐색/삽입/삭제 (0) | 2022.01.24 |
| [자료구조/Java] LinkedList - 조회/추가/삭제 코드구현 (0) | 2022.01.21 |
| [자료구조/Java] Stack (Java구현, 관련 메소드) (0) | 2022.01.02 |
| [자료구조/Java] Queue (Java구현, 관련 메소드) (0) | 2021.12.28 |



